医薬品チームブログ
![]()

新記載要領
照合元データが中国語になっている!
投稿日:2021.06.24
更新日:2024.05.07







こんにちは。営業のNです。
今回もXMLデータを作っているときに遭遇したトラブルについてご案内いたします。
タイトル見て、なんだそれ?と思われたかもしれません。
私もそうです。
流行りの陰謀論でいったらPMDAが中国にのっとられたのかと思いましたよ。
事前にいっておきますがもちろんそんなことはないですよ。
事象を説明します。
ある先発医薬品でXMLの改訂作業をすすめていました。
校了日が近づいてきて、照合元データが公開されたので照合元データをとりこみます。
その後、校正のためXML新旧比較ツールで改訂前と改訂後とを比べました。
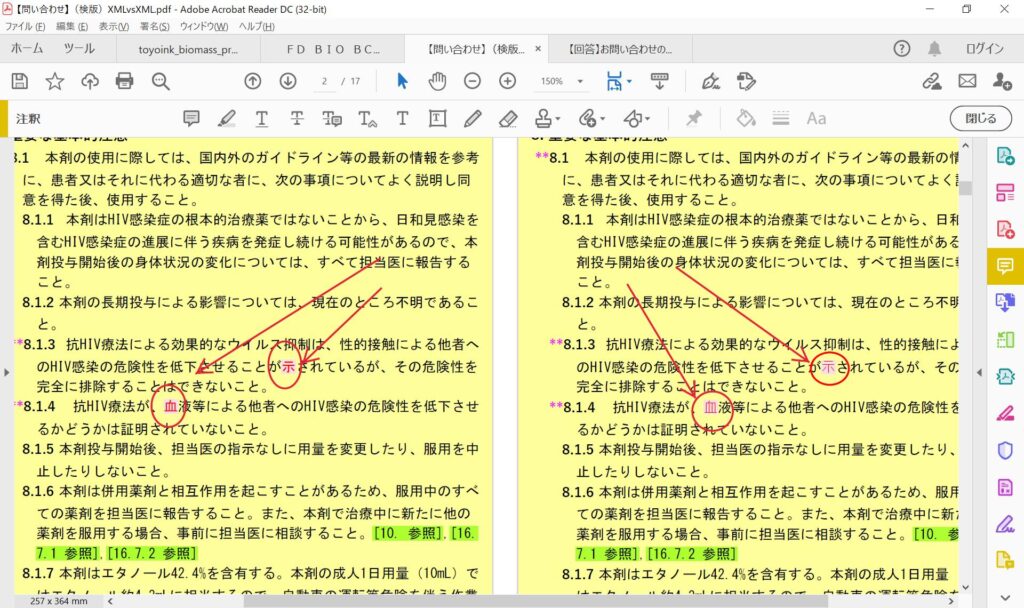
右と左とで比較しています。 通常ここまできたらもう違いはほぼないです。
ところが差分が検知されました。なんだろうと思ってみてみたら、「示」や「血」が違うと検知されています。
ただ、ぱっとみたところ、左右に差分があるようにみえません。
あれ?おかしいな、と思ってもっとよくみてみました。微妙に字形が違いませんか?
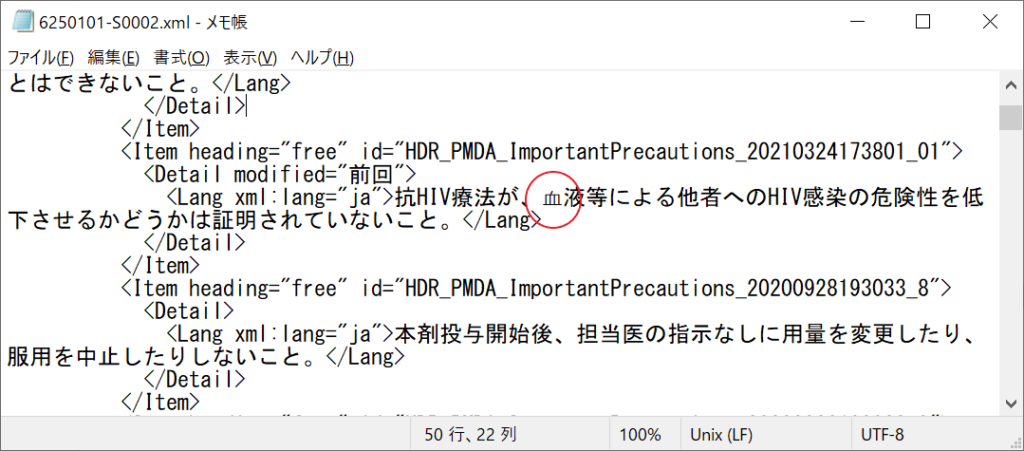
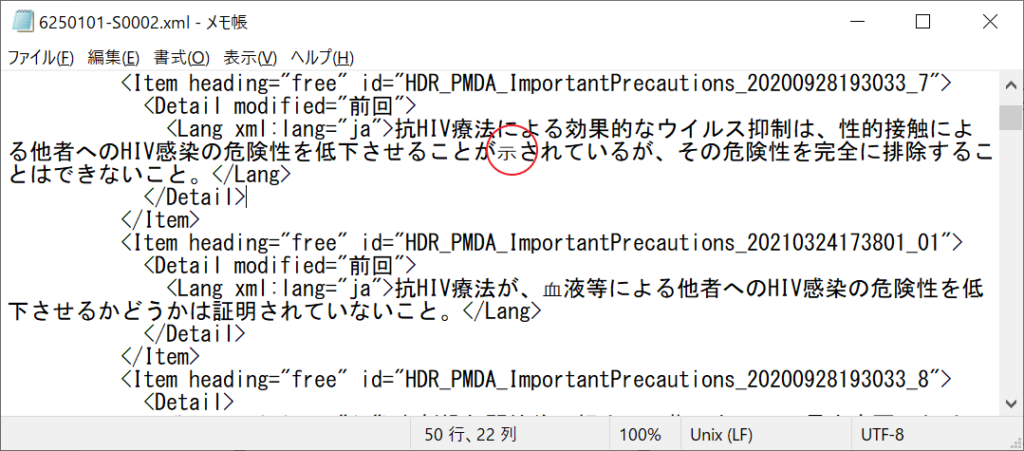
照合元データをテキストエディタで開いて拡大してみます。
よくみたら、いつものものと若干字形が違います。
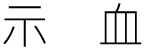
になっています。
これはなんでしょうか?
こちらの文字コードが何かを調べるツールにいれてみます。
普通に使う「示」はUnicodeでは、u793Aが割り当てられています。
こちらの
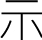
は、u2F70でした。
同じく、普通に使う「血」はUnicodeではu8840です。
こちらの
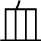
は、u2F8Eでした。
しらべてみたら、康煕部首というものでした。
康熙字典の文字214部首が収録されているUnicodeのブロックだそうで。
無味乾燥な添付文書が急に文学の香りがしてきました。
こういうときは、どうしたらいいのでしょうか?
2つやりかたがあります。
・気にせずこのまま届け出。
そうすると自動受理されます。事なかれ主義感がありますが、前回ブログでも書きましたが照合元データにあわせていくのが基本なのでこちらが無難ではあります。
やはり気になる。通常コードに変えて届け出。
そうなると手動受理になるため、少し時間がかかります。ただ受理がされないことはないと思います。
なぜ康煕部首が急にでてくるのでしょうか?
こればっかりはどういう処理をして照合元データを作っているのかがわからないのでなんともいえません。
私も今回知ったのですが康煕部首に変わってしまうバグはちょこちょこあるようです。
このあたりご参照ください。
「PPTで漢字を5文字以上並べると中国語に変わる」というバグもあるんですね。
私の環境ではみごとに中国語フォントにかわったので驚きました。 みなさんの環境ではいかがですか?
詳しいことは私の手にはおえませんが、やはりオフィスというのはもともと1バイト文字が前提で作られました。
2バイト文字を扱おうと思うといろいろな不都合があるんでしょうね。
さいごに
最後になりますが本ブログは特定の製品などを誹謗する目的ではなく、皆様のXML作成を手助けし、ひいては製薬業界の情報提供活動に寄与する目的で記載しております。
Copyright© Daiko Printing Co. Ltd. All Rights Reserved.